
今天來提一個在課程中一直強調的點「資料是最重要的」。
跟前面的 AI-first 策略呼應,如果模型的預測有錯誤的話,應該繼續收集更多的資料做訓練。

這個部分我認為比較偏向 Google 自己的經驗(因為我沒經驗XD)
像我自己有使用一些 Computer Vision 相關的專案,paper 表現得很好的,在實際使用上還是會遇到很多問題,可能是收集的資料不夠多,或是調模型的能力不夠,或是都有XD。
可能 Google 發現與其花很多時間調整模型,最後上線才發現資料的模式已經改變了,不如把資料收集的基礎設施都建置好,讓模型可以持續獲得最新的資料,讓模型可以持續訓練、更新還比較好。
這個是 ML Surprise,用比例列出一般人預期完成一個 ML 專案的時間分配跟實際上需要的時間。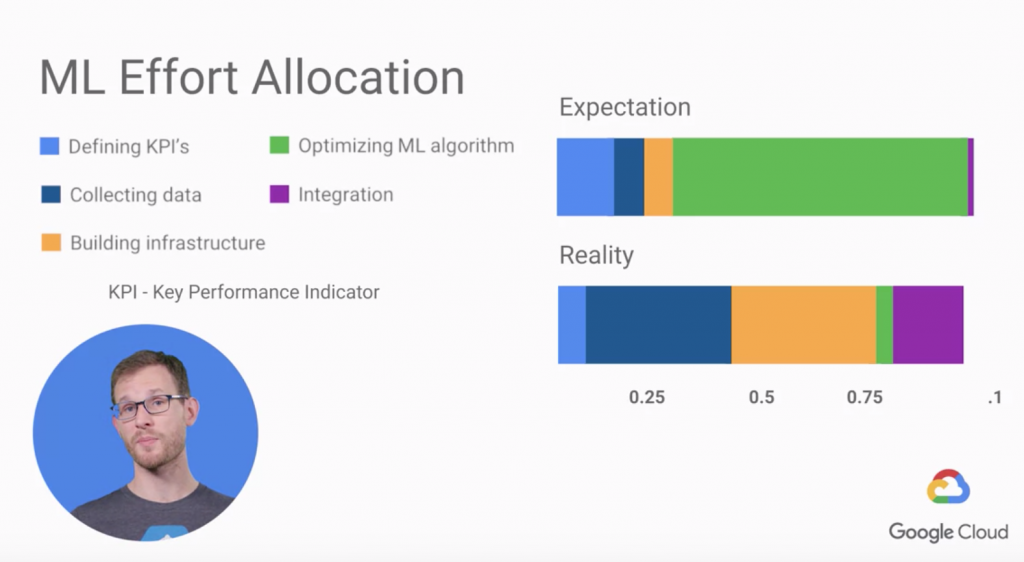
恩...這可能也是大數據出來的,一般人可能沒有機會做這麼多次 ML 專案啊~
再附上上圖的五個大項目常見的痛點:
今天就這樣囉~
